Introduction to MARL
Multi-Agent Reinforcement Learning (MARL) is a generalization of single-agent RL to settings with multiple agents. MARL has many applications, including autonomous driving, robotics, and trading. It can be used to train agents to cooperate, compete, or adapt between cooperation and competition.
Preliminaries
While single-agent RL is modeled using the Markov Decision Process (MDP) framework, MARL can be modeled using Partially Observable Stochastic Games (POSG). In a POSG, we have:
A set of agents \(\mathcal{I} = \{1, 2, ..., n\}\).
Individual observations \(o_i\) received by each agent \(i \in \mathcal{I}\). We use joint observation \(\mathbf{o}\) to refer to the concatenation of the individual observations: \(\mathbf{o} = (o_1, o_2, ..., o_n)\).
Individual actions \(a_i \in \mathcal{A}_i\) . The joint action \(\mathbf{a}\) refers to \((a_1, \dots ,a_n)\).
Global state \(s\) of the environment. The state is more general than the individual observation. For example, in a 2D grid, the state may include the full map, while an agent’s observation only includes nearby cells. A state is not always provided by the simulators, in such cases, it is usually approximated using the joint observation.
Rewards \(R_i\). We usually assume that agents receive a common reward, especially in cooperative settings \(\forall i \in \mathcal{I} R_i= R\).
As in single-agent RL, each agent may have a policy \(\pi_i(.)\) , action-value function \(Q_i(.)\) or a value function \(V_i(.)\).
What makes MARL different from single agent RL ?
MARL inherits multiple concepts and algorithms from single-agent RL, especially the training paradigms: off-policy vs on-policy, policy-based vs value-based, online vs offline. This is reflected in algorithm names: PPO becomes MAPPO (or IPPO), DDPG becomes MADDPG, where the MA prefix refers to Multi-Agent.
However, directly applying single-agent RL algorithms to MARL often yields poor results. This is due to challenges unique to multi-agent settings. Among these challenges, we highlight two main issues:
Non-stationary and Non-Markovian
MDPs by default assume stationary policies and a stationary environment dynamics, alongside the Markov assumption. However, in a multi-agent setting, from the perspective of an individual agent, these assumptions no longer hold.
To see why, consider a single-agent RL (SARL) scenario: the transition probability to a new observation \(o_{t+1}\) from observation \(o_t\) and action \(a_t\) does not change over time. The environment dynamics are stationary, and the policy action probabilities \(\pi(. | o_t)\) are independent of the time step \(t\).
In MARL, multiple agents interact with the environment simultaneously. As a result, the transition probability of agent \(i\) given its local observation \(o^t_i\) and action \(a^t_i\) depends on the actions of the other agents at that time step. Even under the same \(o_i\) and \(a_i\), the transition probabilities can vary over time depending on the behavior of the other agents.
This also impacts the Markov assumption: an individual agent’s observation alone no longer contains enough information to fully predict the next state of the environment. The Markov property is crucial in RL, as it underpins the derivation of the Bellman equations used in most algorithms.
Credit assignement
In environments where a common reward is provided, it can be difficult to determine which agent is responsible for the reward or to what extent each agent contributed. Failing to address the credit assignment problem may lead to a “lazy agent” phenomenon, where only a subset of agents performs most of the work while others contribute little.
Centralized vs Decentralized
Centralized and Decentralized are two important keywords that greatly help us understand and compare different MARL algorithms. They describe which information a neural network (policy, value or action-value network) takes as input. When individual policies are conditioned only on individual observations \(\pi_i(. |o_i)\), we refer to them as decentralized policies, the same applies to action-value functions \(Q_i(o_i,a_i)\). We usually want (or constrained) to have decentralized policies or action-value function, as they are more convenient during deployment.
On the other hand, when a network takes as input the state or the joint observation, we say that it uses central information. In most cases, especially for an actor-critic algorithm, we allow the critic to depend on centralized information, as it’s not used during deployment, and restrict the actor to decentralized observations.
Overview of MARL
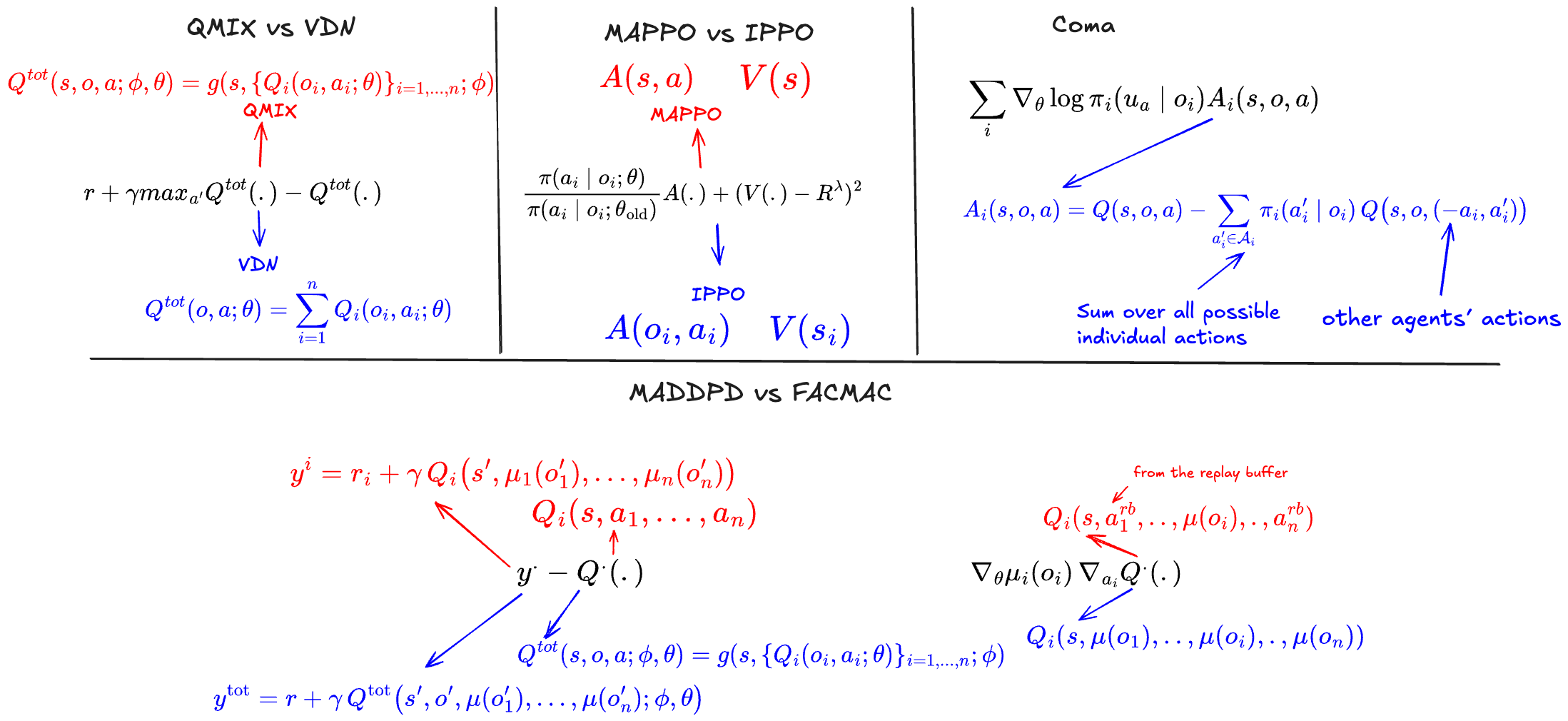
A good way to understand and compare MARL algorithms is to examine the loss functions they optimize and to consider the type of information each network relies on (centralized vs decentralized …).
Learning resources
We assume the reader is already familiar with Deep Reinforcement Learning. If not, we highly recommend the following resources:
Reading main DRL papers alongside CleanRL implementations
This list is not meant to be exhaustive but reflects personal experience. Another very helpful resource, especially from an implementation standpoint, are the discussion in stable-baselines3 issues and pull requests, where you can find many explanations of common implementation tricks used in reinforcement learning.
With a solid understanding of DRL, learning Deep MARL becomes much easier. To approach MARL, we suggest the following:
A must read Multi-Agent Reinforcement Learning: Foundations and Modern Approaches (free PDF version available)
Read the MARL papers that we implement in this project.
We also recommand checking EPyMARL for implementations.