Multi-Agent Deep Deterministic Policy Gradient
Paper link: MADDPG
- Quick facts:
MADDPG is an off-policy actor-critic algorithm.
MADDPG uses a centralized critic with decentralized actors.
MADDPG support continuous and discrete actions.
MADDPG support individual rewards, thus can be used for cooperative, competitive, and mixed.
Background
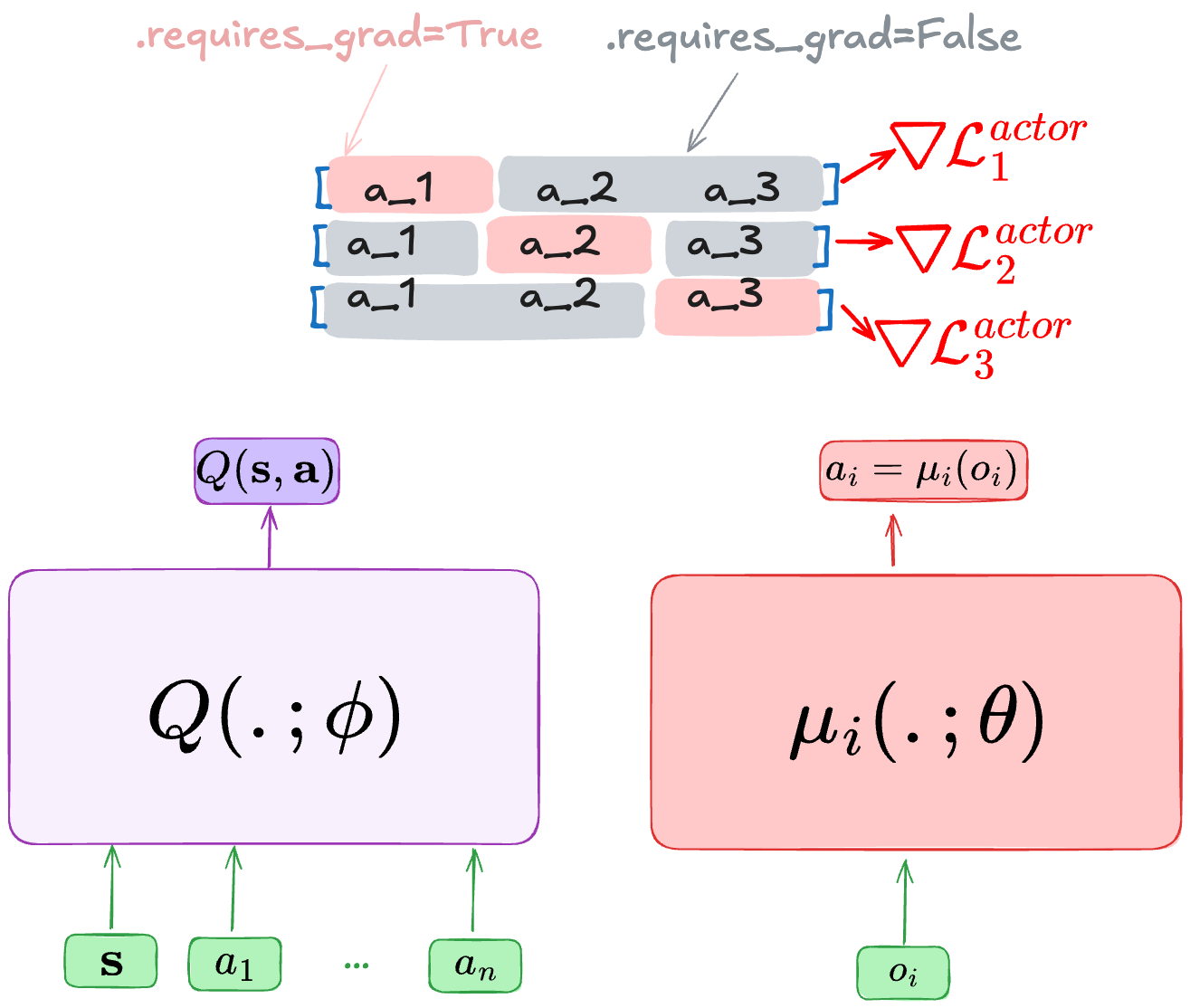
MADDPG is an extension of DDPG to multi-agent settings, using a centralized critic. The critic network takes as input the state information and all agents’ actions \(Q(\mathbf{s},\mathbf{a};\phi)\) and outputs a single value. When using individual rewards, separate centralized critics can be used: \(Q_i(\mathbf{s},\mathbf{a};\phi_i)\). Each agent has a deterministic policy \(\mu(o_i;\theta)\). For discrete actions, we use Gumbel-Softmax to compute gradients with respect to actions.
MADDPG is off-policy, therefor we store transitions while interacting with the environment and sample batches for training the actor and critic. Superscript \(b\) indicates values sampled from the replay buffer.
To train the critic we use the following loss:
To better understand how to update the actor of agent \(i\) , it’s better if we pay close attention to the used gradient:
When computing the gradient of agent \(i\), all the actions are from the replay buffer, except the \(i\)-th action, which is replaced by the current policy.
Pseudocode

Implementations
We implemented four variants of MADDPG:
maddpg.py: MADDPG with a single environment and MLP neural networks.maddpg_multienvs.py: MADDPG with parallel environments and MLP neural networks.maddpg_lstm.py: MADDPG with single environment and recurrent neural networks.maddpg_lstm_multienvs.py: MADDPG with parallel environments and recurrent neural networks.
Additional details:
Replay buffer: The replay buffer stores episodes instead of transitions, therefore, we sample batch of episodes rather than a batch of transitions. Each episode is stored as
{"obs": [],"actions":[],"reward":[],"states":[],"done":[],"next_avail_actions":[]}. We storenext_avail_actionsto accurately compute TD targets for the best available next action.Discrete actions: we only support discrete actions for now
Gumbel-Softmax: We use PyTorch’s
torch.nn.functional.gumbel_softmax. During episode collection and critic training, sethard=True; during actor training, sethard=Falsefor better results.Parallel environments: Parallel environments are not as useful for off-policy algorithms as for on-policy settings as we sample from a replay buffer. In order to keep comparable number of network updates, we train for multiple epochs in each training step by adding a
n_epochsargument. We log the number of network updates under the nametrain/num_updates.Parallel environments with RNNs: When using multiple environments in parallel, some episodes may complete before others. We track alive environments at each timestep. This is critical for RNN policies, as the hidden state is initially sized
(num_envs x num_agents, hidden_dim)but only updated for(num_alive_envs x num_agents, hidden_dim)when some episodes finish.RNN training : We use truncated backpropagation through time (TBPTT) to train the RNN network. You can set the length of the sequence using
tbptt.
Logging
We record the following metrics:
rollout/ep_reward : Mean episode reward during environment rollouts.
rollout/ep_length : Mean episode length during rollouts.
rollout/num_episodes : Total number of completed episodes until the current step.
rollout/battle_won (SMAClite only): Fraction of battle won by SMAC agents
train/critic_loss : The critic loss at the current optimization step.
train/actor_loss : The actor loss at the current optimization step.
train/actor_gradients : Magnitude of gradients of actor network.
train/critic_gradients : Magnitude of gradients of critic network.
train/num_updates : Total number of network updates until the current step.
eval/ep_reward : Mean episode reward during evaluation.
eval/std_ep_reward : Standard deviation of episode rewards during evaluation.
eval/ep_length : Mean episode length during evaluation.
eval/battle_won ( SMAClite only): Fraction of battles won during evaluation episodes.
Documentation
- class cleanmarl.maddpg.Args(env_type='smaclite', env_name='3m', env_family='mpe', agent_ids=True, gamma=0.99, buffer_size=5000, batch_size=10, normalize_reward=False, actor_hidden_dim=32, actor_num_layers=1, critic_hidden_dim=128, critic_num_layers=1, train_freq=1, optimizer='Adam', learning_rate_actor=0.0003, learning_rate_critic=0.0003, total_timesteps=1000000, target_network_update_freq=1, polyak=0.005, clip_gradients=-1, log_every=10, eval_steps=50, num_eval_ep=5, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)
- Parameters:
env_type (str) – Type of the environment:
smaclite,pzfor PettingZoo, etc.env_name (str) – Name of the environment (
3m,simple_spread_v3, etc.)env_family (str) – Environment family when using PettingZoo (
sisl,mpe…).agent_ids (bool) – Include agent IDs (one-hot vector) in observations.
gamma (float) – Discount factor for returns.
buffer_size (int) – Number of episodes in the replay buffer.
batch_size (int) – Batch size for training.
normalize_reward (bool) – Normalize the rewards if True.
actor_hidden_dim (int) – Hidden dimension of the actor network.
actor_num_layers (int) – Number of hidden layers in the actor network.
critic_hidden_dim (int) – Hidden dimension of the critic network.
critic_num_layers (int) – Number of hidden layers in the critic network.
train_freq (int) – Train the network each
train_freqepisodes of the environment.optimizer (str) – Optimizer for both actor and critic.
learning_rate_actor (float) – Learning rate for the actor network.
learning_rate_critic (float) – Learning rate for the critic network.
total_timesteps (int) – Total number of environment steps during training.
target_network_update_freq (int) – Update the target network each
target_network_update_freqepisodepolyak (float) – Polyak coefficient for target network updates.
clip_gradients (float) –
0<for no clipping and0>to clip gradients at this value.log_every (int) – Log rollout statistics every
log_everyepisode.eval_steps (int) – Evaluate the policy every
eval_stepsepisode.num_eval_ep (int) – Number of evaluation episodes.
use_wnb (bool) – Enable logging to Weights & Biases if True.
wnb_project (str) – Weights & Biases project name.
wnb_entity (str) – Weights & Biases entity name.
device (str) – Device to use (
cpu,gpu,mps).seed (int) – Random seed for reproducibility.
- class cleanmarl.maddpg_multienvs.Args(env_type='smaclite', env_name='3m', env_family='mpe', agent_ids=True, num_envs=4, gamma=0.99, buffer_size=5000, batch_size=10, normalize_reward=False, actor_hidden_dim=32, actor_num_layers=1, critic_hidden_dim=128, critic_num_layers=1, epochs=4, optimizer='Adam', learning_rate_actor=0.0003, learning_rate_critic=0.0003, total_timesteps=1000000, target_network_update_freq=1, polyak=0.01, clip_gradients=-1, log_every=10, eval_steps=50, num_eval_ep=5, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)
- Parameters:
num_envs (int) – Number of parallel environments
epochs – Number of batches sampled in one update
- class cleanmarl.maddpg_lstm.Args(env_type='smaclite', env_name='3m', env_family='mpe', agent_ids=True, gamma=0.99, buffer_size=5000, batch_size=10, normalize_reward=False, actor_hidden_dim=32, actor_num_layers=1, critic_hidden_dim=128, critic_num_layers=1, train_freq=1, optimizer='Adam', learning_rate_actor=0.0006, learning_rate_critic=0.0006, total_timesteps=1000000, target_network_update_freq=1, polyak=0.005, clip_gradients=-1, tbptt=10, log_every=10, eval_steps=50, num_eval_ep=5, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)
- Parameters:
tbptt (int) – Chunk size for Truncated Backpropagation Through Time (TBPTT).
- class cleanmarl.maddpg_lstm_multienvs.Args(env_type='smaclite', env_name='3m', env_family='mpe', agent_ids=True, num_envs=4, gamma=0.99, buffer_size=5000, batch_size=10, normalize_reward=False, actor_hidden_dim=32, actor_num_layers=1, critic_hidden_dim=128, critic_num_layers=1, optimizer='Adam', learning_rate_actor=0.0003, learning_rate_critic=0.0003, total_timesteps=1000000, target_network_update_freq=1, polyak=0.01, epochs=4, clip_gradients=-1, tbptt=10, log_every=10, eval_steps=50, num_eval_ep=5, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)