Monotonic Value Function Factorization
Paper link: QMIX
- Quick facts:
QMIX is an off-policy and value-based algorithm.
QMIX works only with discrete actions.
Background
VDN allows us to derive decentralized policies from a centralized action-value function. However, it has two major limitations that QMIX addresses:
The additive assumption is too restrictive. VDN limits the representational capacity of the centralized value function by enforcing a simple sum of individual Q-values, rather than allowing a more flexible non-linear combination.
VDN cannot exploit additional information from the global state when available.
Both VDN and QMIX share the same objective: to extract decentralized policies from a centralized action-value function. While VDN supports only linear decomposition, QMIX supports complex, non-linear decompositions.
The key idea of QMIX is that decentralized policies can be extracted from a centralized network, as long as a consistency property is satisfied. Specifically, the global argmax over the centralized action-value function \(Q^{tot}\) should be equivalent to performing individual argmax operations on each local value function \(Q_i\):
Our goal is to find a mixing function \(g\) that satisfies (1), such that:
It is worth noting that VDN already satisfy this property.
A sufficient (but not necessary) condition for a function \(g\) to satisfy this property is to enforce monotonicity of \(Q^{tot}\) whit respect to \(Q_i\):
In general, for a neural network \(g(\cdot; \phi)\) to be monotonic with respect to its inputs, all its weights must be non-negative. QMIX uses this property to design a monotonic mixing function.
To achieve this, QMIX uses three neural networks:
Individual action-value networks: \(Q_i(o_i, a_i)\)
A hypernetwork, which takes the global state \(s\) as input and generates a set of positive weights \(\phi\). These weights parameterize the mixing network.
A mixing network, whose parameters are produced by the hypernetwork, takes the individual Q-values as input and outputs the centralized value \(Q^{tot}\).
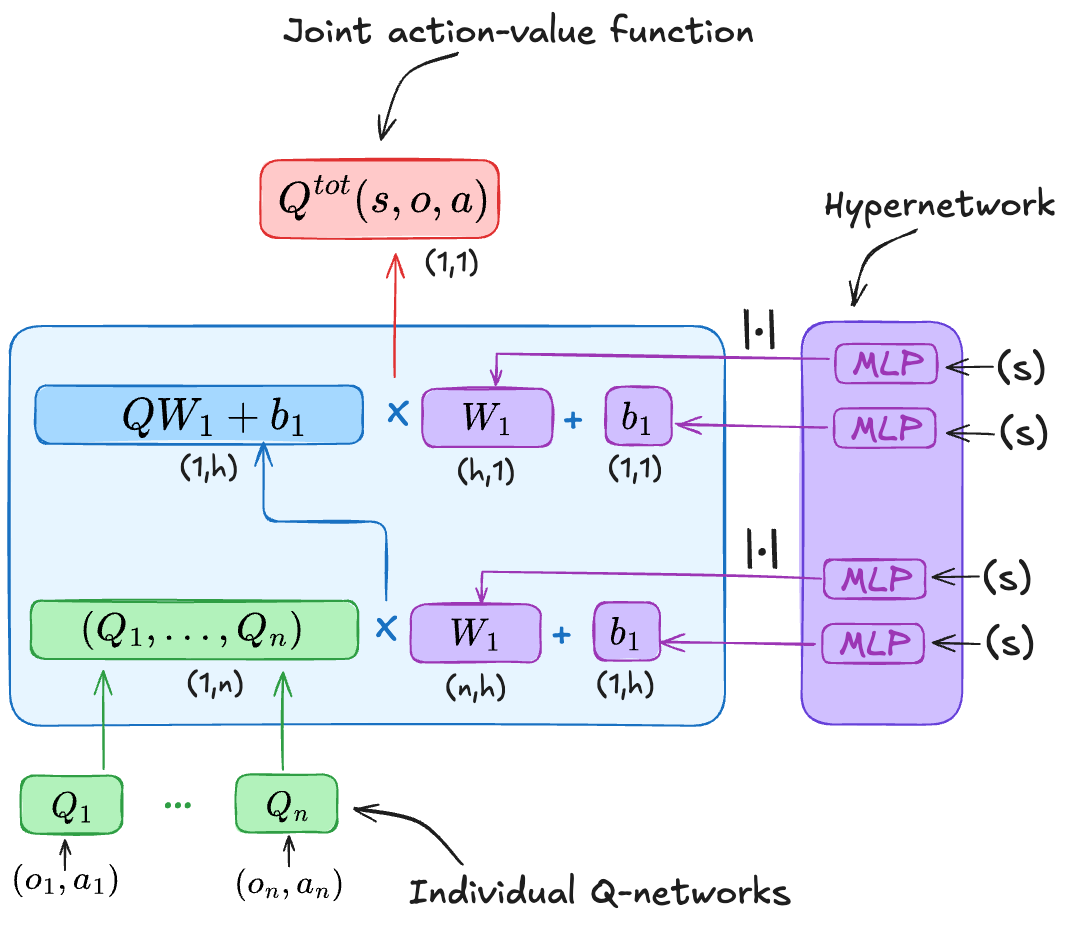
Finally, the networks are trained by minimizing the following TD loss:
Pseudocode

Implementations
We implemented four variants of QMIX:
qmix.py: QMIX with a single environment and MLP neural networks.qmix_memefficient.py: QMIX with a single environments and MLP neural networks, but with a memory-efficient replay buffer.qmix_multienvs.py: QMIX with parallel environments and MLP neural networks.qmix_lstm.py: QMIX with single environment and recurrent neural networks.
Additional details:
Replay buffer: The replay buffer stores episodes instead of individual transitions. Therefore, we sample batches of episodes rather than batches of transitions. Each episode is initially stored as a dictionary with the following keys (except in
qmix_memefficient.py):{"obs": [], "actions": [], "reward": [], "next_obs": [], "states": [], "next_states": [], "done": [], "next_avail_actions": []}. This is not memory-efficient. For example, the observation att=1is stored twice, once asobsand once asnext_obs. A more memory-efficient strategy is implemented inqmix_memefficient.py, where each episode is stored as:{"obs": [], "actions": [], "reward": [], "states": [], "done": [], "next_avail_actions": []}. We need to storenext_avail_actionsto correctly compute TD targets, since the TD update requires the value of the best available next action.Parallel environments: Parallel environments are less critical for off-policy algorithms than for on-policy settings, since training samples are drawn from a replay buffer. To maintain a consistent number of network updates, we perform multiple epochs per training step, configurable with the
n_epochsargument. The total number of network updates is logged undertrain/num_updates.RNN training : We use Truncated Backpropagation Through Time (TBPTT) to train the RNN network. You can set the length of the sequence using
tbptt.
Logging
We record the following metrics:
rollout/ep_reward : Mean episode reward during environment rollouts.
rollout/ep_length : Mean episode length during rollouts.
rollout/epsilon : Current exploration epsilon.
rollout/num_episodes : Total number of completed episodes until the current step.
rollout/battle_won (SMAClite only): Fraction of battle won by SMAC agents
train/loss : Training loss at the current optimization step.
train/grads : Magnitude of gradients of the VDN networks.
train/num_updates : Total number of network updates until the current step.
eval/ep_reward : Mean episode reward during evaluation.
eval/std_ep_reward : Standard deviation of episode rewards during evaluation.
eval/ep_length : Mean episode length during evaluation.
eval/battle_won ( SMAClite only): Fraction of battles won during evaluation episodes.
Documentation
- class cleanmarl.qmix.Args(env_type='smaclite', env_name='3m', env_family='mpe', agent_ids=True, buffer_size=5000, total_timesteps=1000000, gamma=0.99, train_freq=1, optimizer='Adam', learning_rate=0.0005, batch_size=10, start_e=1, end_e=0.025, exploration_fraction=0.05, hidden_dim=64, hyper_dim=64, num_layers=1, target_network_update_freq=1, polyak=0.01, normalize_reward=False, clip_gradients=-1, log_every=10, eval_steps=50, num_eval_ep=5, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)
- Parameters:
env_type (str) – Type of the environment:
smaclite,pzfor PettingZoo,lbffor Level-based Foraging.env_name (str) – Name of the environment (
3m,simple_spread_v3Foraging-2s-10x10-4p-2f-v3…)env_family (str) – Env family when using a PettingZoo environment (
sisl,mpe…)agent_ids (bool) – Include agent IDs (one-hot vector) in observations
buffer_size (int) – The number of episodes in the replay buffer
total_timesteps (int) – Total steps in the environment during training
gamma (float) – Discount factor
train_freq (int) – Train the network each
train_freepisodes of the environmentoptimizer (str) – The optimizer
learning_rate (float) – Learning rate
batch_size (int) – Batch size
start_e (float) – The starting value of epsilon, for exploration
end_e (float) – The end value of epsilon, for exploration
exploration_fraction (float) – The fraction of
total-timestepsit takes from to go fromstart_etoend_ehidden_dim (int) – Hidden dimension of \(Q_i\):
hyper_dim (int) – Hidden dimension of the hyper-network
num_layers (int) – Number of layers
target_network_update_freq (int) – Update the target network each
target_network_update_freqstep in the environmentpolyak (float) – Polyak coefficient when using polyak averaging for target network update
normalize_reward (bool) – Normalize the rewards if True
clip_gradients (float) –
0<for no gradients clipping and0>if clipping gradients atclip_gradientslog_every (int) – Log rollout stats every
log_everyepisodeeval_steps (int) – Evaluate the policy each
eval_stepsepisodenum_eval_ep (int) – Number of evaluation episodes
use_wnb (bool) – Logging to Weights & Biases if True
wnb_project (str) – Weights & Biases project name
wnb_entity (str) – Weights & Biases entity name
device (str) – Device (
cpu,gpu,mps) We only support CPU training for nowseed (int) – Random seed
- class cleanmarl.qmix_memefficient.Args(env_type='smaclite', env_name='3m', env_family='mpe', agent_ids=True, buffer_size=5000, total_timesteps=1000000, gamma=0.99, train_freq=1, optimizer='Adam', learning_rate=0.0005, batch_size=10, start_e=1, end_e=0.025, exploration_fraction=0.05, hidden_dim=64, hyper_dim=64, num_layers=1, target_network_update_freq=1, polyak=0.01, normalize_reward=False, clip_gradients=-1, log_every=10, eval_steps=50, num_eval_ep=5, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)
- class cleanmarl.qmix_multienvs.Args(env_type='smaclite', env_name='MMM', env_family='mpe', num_envs=4, agent_ids=True, buffer_size=5000, total_timesteps=1000000, gamma=0.99, train_freq=2, optimizer='Adam', learning_rate=0.0005, batch_size=32, start_e=1, end_e=0.025, exploration_fraction=0.05, hidden_dim=64, hyper_dim=64, num_layers=1, target_network_update_freq=1, polyak=0.005, clip_gradients=-1, n_epochs=2, normalize_reward=False, log_every=10, eval_steps=50, num_eval_ep=5, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)
- class cleanmarl.qmix_lstm.Args(env_type='smaclite', env_name='3m', env_family='mpe', agent_ids=True, buffer_size=10000, total_timesteps=1000000, gamma=0.99, train_freq=1, optimizer='Adam', learning_rate=0.0008, batch_size=10, start_e=1, end_e=0.025, exploration_fraction=0.05, hidden_dim=64, hyper_dim=64, num_layers=1, target_network_update_freq=1, polyak=0.005, normalize_reward=False, clip_gradients=-1, tbptt=10, log_every=10, eval_steps=50, num_eval_ep=10, use_wnb=False, wnb_project='', wnb_entity='', device='cpu', seed=1)
- Parameters:
tbptt (int) – Chunk size for Truncated Backpropagation Through Time (TBPTT).